– Exam-1: Assigned October 9th; Due 11:59pm October 15th
Announcements
– All videos are live
– All solutions are posted
– Exam equation sheet is posted
Warm Up: Review
Hypothesis testing: What is…
– Null hypothesis
– Alternative hypothesis
– Sample statistic
– Test statistic
– p-value
– alpha
– Decision
– Conclusion
Warm Up: Review
Hypothesis testing: What is…
– Null hypothesis - assumption about the population
– Alternative hypothesis - our research question
– Sample statistic - our calculated statistic from our data
– Test statistic - also called standardized statistic (Z or t)
– p-value (probability of observing our stat, or something more extreme, given the null is true)
– alpha - “type-1 error” or threshold to compare vs p-value
– Decision - Reject or fail to reject the null
– Conclusion - Strong or weak evidence to conclude the alternative
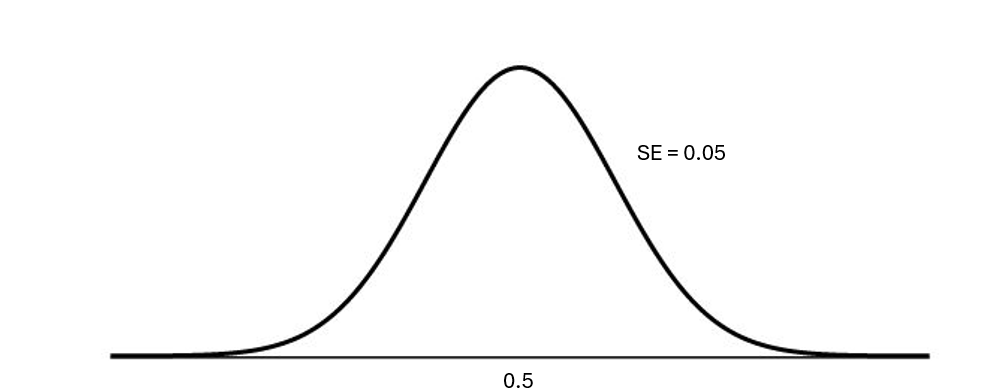
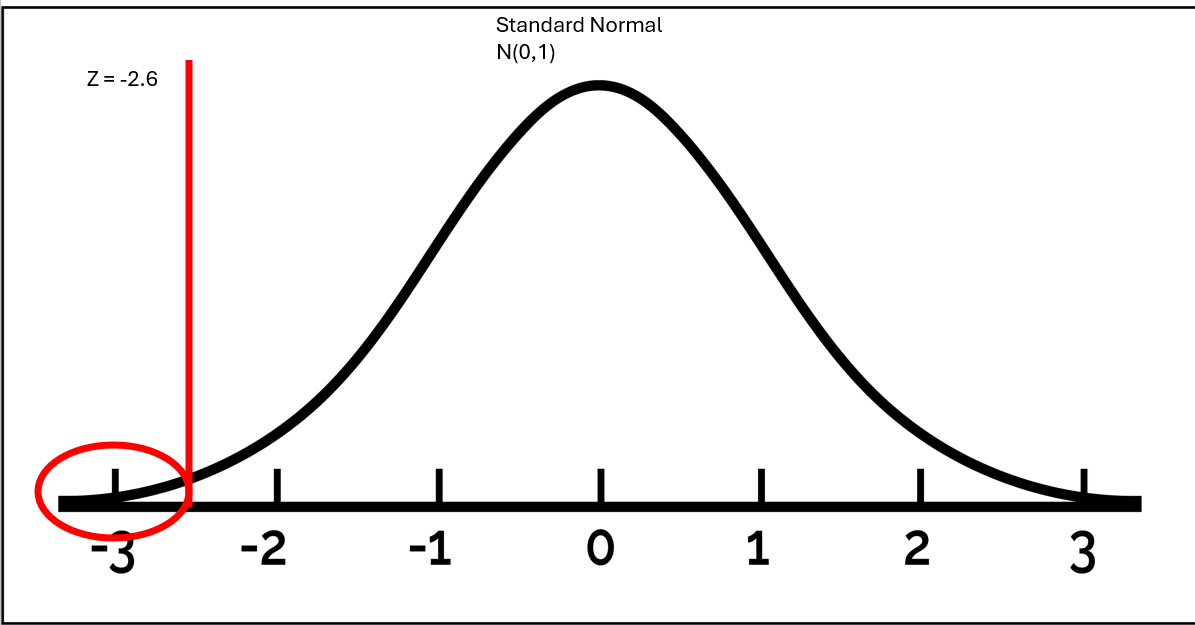
Sampling distribution under the null
Here is the approximated null distribution. And we can calculate the p-value straight from here!
Z = \(\frac{\hat{p} - \pi_o}{SE}\)
Z = \(\frac{.37 - .5}{0.05}\) = -2.61
These two are equivalent because as soon as we “know \(\pi\)”, we also know the variance of our sampling distribution … meaning with know that the our statistic \(\hat{p}\) is ~ normal.
This is not true for hypothesis tests for the mean. We can’t say that \(\bar{x}\) ~ t.
So when we do hypothesis testing for the mean, you will always standardize so our t-stat ~ \(t_\text{df}\) (or do a simulation test).
Warm Up: Review
Confidence intervals: What is…
– The purpose
– The equation
– Confidence level
– Interpretation
– Meaning of confidence
Warm Up: Review
Confidence intervals: What is…
– The purpose - to estimate!
– The equation \(stat \pm \text{margin of error}\)
– Confidence level - The percentage of the distribution in between your upper and lower bound
– Interpretation - We are ___% confident that our true parameter is within (lower, upper). Note: we need to think about direction when looking at a difference!
– Meaning of confidence - In the long run… if we make many 95% confidence intervals, we would expect 95% of all confidence intervals to cover the true parameter.
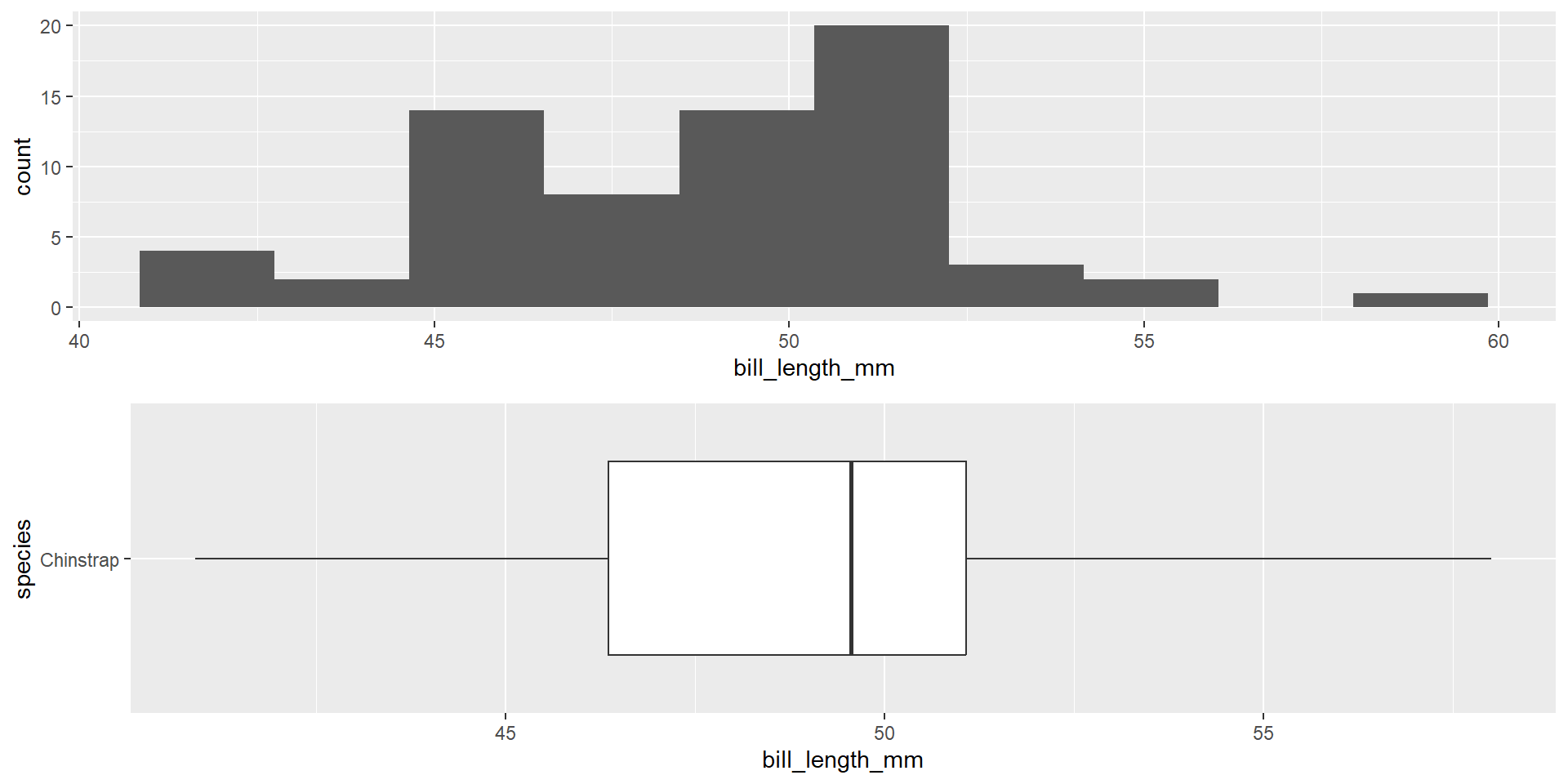
Context
We are going to use a familiar data set (penguins) to demonstrate these theory based procedures. In this example, we are interested in exploring if the species of the penguin impacts the bill length (mm) of the penguin on the Palmer island. We will be looking at the Chinstrap and Gentoo species of penguin. We are interested in researching if there is a difference in bill length between the Gentoo penguins the Chinstrap penguins.